Introduction
- socket address: For TCP/IP, the socket address is IP address and port number.
- a socket is the file descriptor;
- local_addr is the socket address on local computer.
- remote_addr is the socket address on remote computer.
The Socket States
- detached: a socket file discriptor is created, but there is no socket address associated. This socket conceptually cannot do anything.
- If you call sendto(remote_addr), socket implementation automatically binds it to a good local socket address and moves to bound state, before sending data.
- connect(remote_addr) moves directly to connected state.
- bound: the socket is associated with a local socket address (e.g. IP and port). For connection-less socket, you can now receive data from remote party because they can address to you. You can send data as long as you know the remote party’s socket address. Note that when bind() a socket, you can specify “any” IP (INADDR_ANY for IPv4, and in6addr_any for IPv6); when a message from client arrives, it can come though any network interface if your host has multiple interfaces (with different IPs). In bound state, you can choose to bind to a port together with a specific IP, or a floating “any” IP.
- listening: This is like a special bound state for a connection-oriented socket on server.
- connected: A connected socket has the full information about both local and remote addresses.
Connection-less Socket (like UDP)
- The server uses socket() -> bind() so it can wait for incoming messages;
- The client uses socket() then it can use sendto(remote_addr) / sendmsg(remote_addr) to send a message to remote server. The socket implementation automatically binds the socket to a local socket address. You can also manually bind() it before using sendto(remote_addr) / sendmsg(remote_addr), but you have to choose IP / port carefully yourself.
- The receiver end would expose sender’s socket address when recvfrom() / recvmsg() is called. This address is again used to reply the message, if reply is needed.
- Therefore a connection-less socket can stay in bound state all the time.
- It is however possible to move the connection-less socket to connected state, by calling connect(remote_addr). After that, you can send message with write()/send() without specifying remote_addr explicitly. You can call connect() again to let the socket point to a different remote socket address, or connect(null) to clear that association to return to bound state.
Connection-Oriented Socket (like TCP)
- The server uses socket() -> bind() -> listen() -> accept() sequence.
- The client uses socket() -> connect(remote_addr).
- The client may use socket() -> bind(local_addr) -> connect(remote_addr), but binding is automatically done if it uses socket() -> connect(remote_addr).
- The server’s listening socket is not for data communication. It serves as a mother socket, and the only purpose is to take in a new incoming connection from client. If that incoming connection is accepted, a new server side socket is spawned in connected state. The client side socket is also moved into connected state, associated with the socket address of the new server side socket in connected state. The listening server socket never moves into connected state.
- Once the connection is established, both client and server now have a socket in connected state, and they can use read()/write()/send()/recv() to exchange data.
The State Machine Diagram
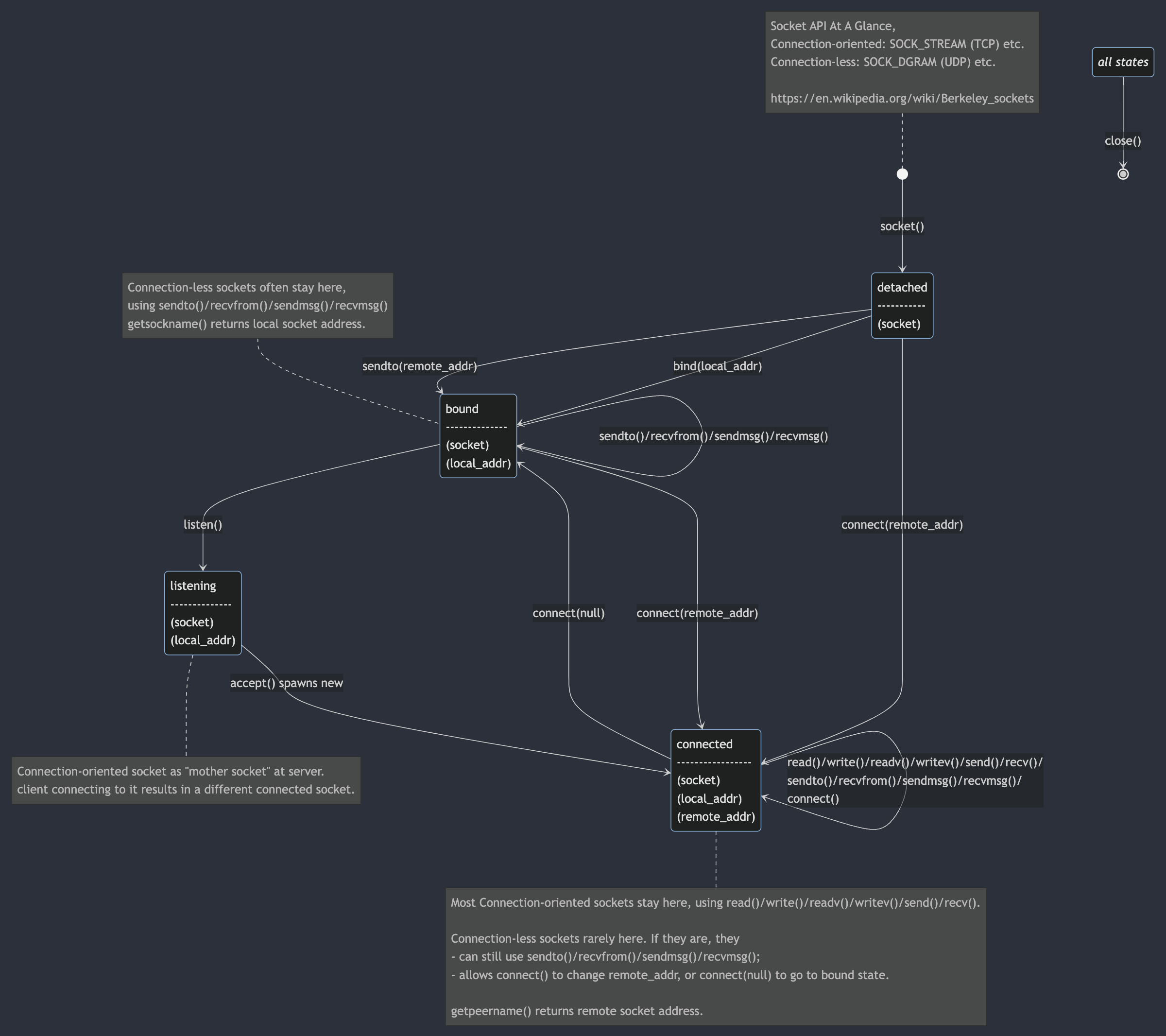
The state machine diagram is generated by Mermaid tool, see https://mermaid.js.org/syntax/stateDiagram.html. There is the Online Mermaid Editor you can try at https://mermaid.live/, paste the following in there:
%% Mermaid diagram https://mermaid.js.org/syntax/stateDiagram.html
stateDiagram-v2
detached: detached\n-----------\n(socket)
bound: bound\n--------------\n(socket)\n(local_addr)
listening: listening\n--------------\n(socket)\n(local_addr)
connected: connected\n-----------------\n(socket)\n(local_addr)\n(remote_addr)
all: all states
classDef VirtualState font-style:italic;
[*] --> detached : socket()
detached --> bound : bind(local_addr)
detached --> bound : sendto(remote_addr)
bound --> bound : sendto()/recvfrom()/sendmsg()/recvmsg()
detached --> connected : connect(remote_addr)
bound --> listening: listen()
listening --> connected: accept() spawns new
bound --> connected : connect(remote_addr)
connected --> connected: read()/write()/readv()/writev()/send()/recv()/\nsendto()/recvfrom()/sendmsg()/recvmsg()/\nconnect()
connected --> bound: connect(null)
all:::VirtualState --> [*] : close()
note left of [*]
Socket API At A Glance,
Connection-oriented: SOCK_STREAM (TCP) etc.
Connection-less: SOCK_DGRAM (UDP) etc.
https://en.wikipedia.org/wiki/Berkeley_sockets
end note
note left of bound
Connection-less sockets often stay here,
using sendto()/recvfrom()/sendmsg()/recvmsg()
getsockname() returns local socket address.
end note
note right of listening
Connection-oriented socket as "mother socket" at server.
client connecting to it results in a different connected socket.
end note
note right of connected
Most Connection-oriented sockets stay here, using read()/write()/readv()/writev()/send()/recv().
Connection-less sockets rarely here. If they are, they
- can still use sendto()/recvfrom()/sendmsg()/recvmsg();
- allows connect() to change remote_addr, or connect(null) to go to bound state.
getpeername() returns remote socket address.
end note
Some C++ wrapper code for socket is in C++ Wrapper for Socket API.